Yurii PanivI'm a PhD student in Computer Science at the Ukrainian Catholic University (UCU), working on developing
unsupervised and semi-supervised methods to obtain high-quality machine
learning models using
minimal data.
This is important for languages that don't have the same amount of data available as for English, bringing those communities equal economic opportunities.
|

|
🪄 ResearchHere is a list of my research projects, exploring how to shorten the gap between high-resource and low-resource languages in natural language processing. |
|
Sovereign Large Language Models: Advantages, Strategy and RegulationsMykhailo Bondarenko, Sviatoslav Lushnei, Yurii Paniv, Oleksii Molchanovsky, Mariana Romanyshyn, Yurii Filipchuk, Artur Kiulian arxiv, 2025 📖 arxiv I was a PM for this policy research paper. This report analyzes key trends, challenges, risks, and opportunities associated with the development of Large Language Models (LLMs) globally. It examines national experiences in developing LLMs and assesses the feasibility of investment in this sector. Additionally, the report explores strategies for implementing, regulating, and financing AI projects at the state level. We analyzed more than 18 macroregions, covering about 85% of the world’s population. |
|
Benchmarking Multimodal Models for Ukrainian Language Understanding Across Academic and Cultural DomainsYurii Paniv, Artur Kiulian, Dmytro Chaplynskyi, Mykola Khandoga, Anton Polishko, Tetiana Bas, Guillermo Gabrielli arxiv, 2024 📖 arxiv Here we benchmarked most of the existing multimodal LLMs for Ukrainian language for academic performance and cultural understanding to establish an understanding what models perform best for Ukrainian in multi-modal scenario. We gathered a national exam dataset for this purpose. |
|
Setting up the Data Printer with Improved English to Ukrainian Machine TranslationYurii Paniv, Dmytro Chaplynskyi, Nikita Trynus, Volodymyr Kyrylov Third Ukrainian Natural Language Processing Workshop (UNLP) @ LREC-COLING 2024, 2024 📖 arxiv / code / 🤗 model / 🕹️ demo Here we trained a new model for English to Ukrainian machine translation, utilizing unsupervised data selection to reach SOTA performance on English-Ukrainian translation (FLORES test set). High-quality translations should help in the development of the Ukrainian language processing tools and resources. |

|
Unsupervised Data Validation Methods for Efficient Model TrainingYurii Paniv arxiv, 2023 📖 arxiv The updated version of my research proposal with motivation why and how we need to focus on bringing state-of-the-art performance to low-resource languages and domains. Old version of proposal can be found here. |
🤗 Open Source ProjectsThese are projects that I have contributed to or created, that led to my research work. |

|
UAlpacaGitHub 2023-03-28 code / 🤗 model / 🕹️ demo First Ukrainian instruction-tuned language models and datasets. This is a first publicly-known exploration of extracting Ukrainian-language capabilities in Large Language Models. |
|
Crimean Tatar Text-to-SpeechGitHub 2022-10-24 code / 🤗 model / 🕹️ demo Experiment to bring natural-sounding Text-to-Speech to low-resource Crimean Tatar language with just 2 hours of audio data, validating a recipe for other low-resource languages. Showcased on national TV in Ukraine!
|

|
Ukrainian Question and Answering with BERTGitHub 2022-05-30 code / 🤗 model Extractive Ukrainian Question Answering models with BERT, useful for analyzing Ukrainian text. |
|
Ukrainian Text-to-SpeechGitHub 2021-10-01 code / 🤗 model / 🕹️ demo The most popular open source Ukrainian Text-to-Speech model with completely open and MIT-licensed stack.
|
|
Ukrainian Speech-to-TextGitHub 2020-08-10 code / 🤗 model / 🕹️ demo Speech-to-Text training scripts for Ukrainian WER 12,22%. Outdated by now, there are a lot of better models here. |
⚙️ Industry experienceOverall I have 9+ years of industry experience, spanning recommendation systems and data analysis for retail, automatic microchip quality assurance, financial domain and serving and processing vast amounts of geospatial data. More details and up-to-date information could be found on my LinkedIn. |
🤝 Other ProjectsThese include coursework, side projects and unpublished research work. |
|
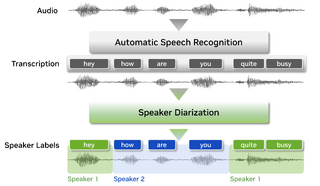
Audio Processing Course Lecturer at UCULecturer 2025-03-24 🌐 website / 📺 video I was a guest lecturer at UCU Audio Processing Course, talking about Speaker Diarization. |

|
Advisor for several BSc and MSc studentsAdvisor 2025-02-16 I’m currently an advisor for several BSc and MSc students at Ukrainian Catholic University, helping them with their research projects in the field of NLP, processing text and speech data in particular. |

|
GenAI Course Lecturer at UCULecturer 2024-10-25 🌐 website I was one of the authors and lecturers for GenAI course at Ukrainian Catholic University in Fall 2024. Alongside my colleagues Nazarii Drushchak and Igor Babin we introduced students to generative NLP and CV concepts, tools and latest research. Course syllabus is available here. |
|
'Text-to-Speech Speedrun' LectureLecturer 2024-03-25 📺 video Was a public speaker on 2 events in the same month with the same topic: «Text-to-Speech speedrun». |

|
ContribuLing 2022 (Wikimedia Foundation conference) SpeakerLecturer 2022-04-20 Topic: «Recognition and synthesis of Ukrainian language» |
|
Design and source code from Jon Barron's website |